
7月17日,上海人工智能实验室公布了针对7款国内外主流AI大模型的高考全科目测试结果。
本次测评的相关负责人介绍,“当前大模型仍存在很大的局限性。组织AI大模型参加正式的高考题测,可以鉴定当前大模型的真实水平,找准问题,持续推进技术进步。”

现在将测评的全科成绩结果公布如下:
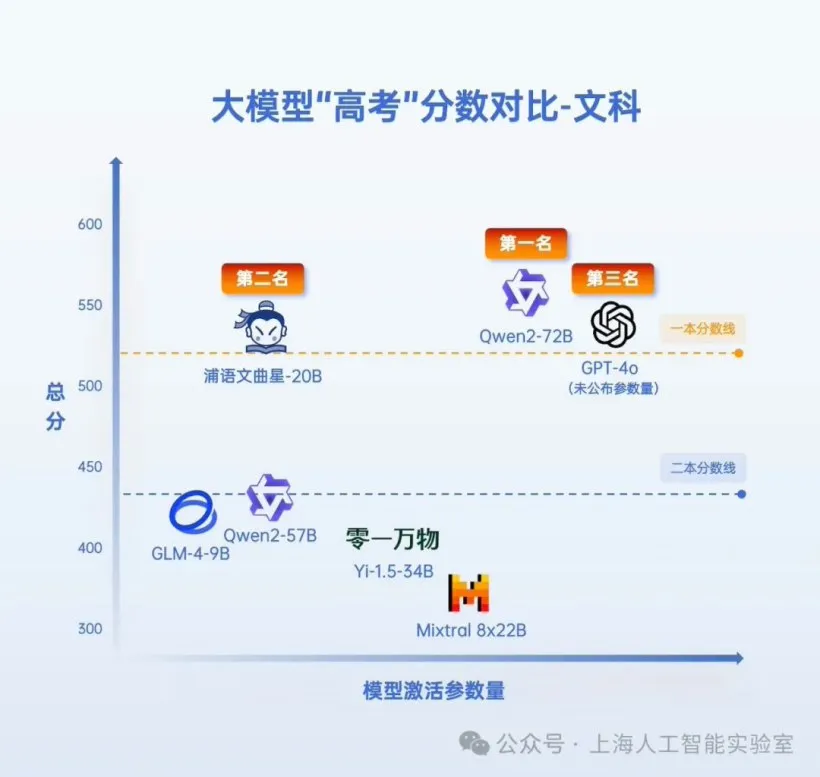
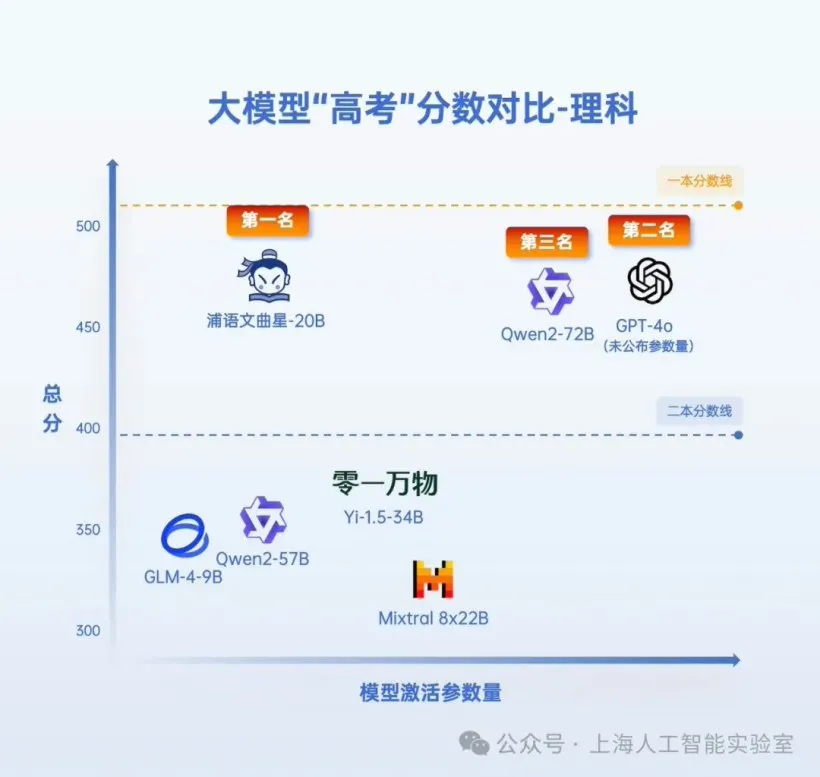
测试结果显示,书生·浦语2.0系列的文曲星大模型(浦语文曲星)、阿里通义千问大模型Qwen2-72B以及OpenAI的GPT-4o再次包揽文科、理科前三甲;前三名「AI考生」的文科、理科成绩分别超过了河南省高考今年的一本线与二本线。
之所以采用河南省的高考录取分数线,是因为该省考生数量样本足够大,可以最准确呈现大模型的真实水平。
本次参与「AI高考」的所有AI大模型的得分与排名情况公布如下:

据介绍,此次评测具备如下特征:
全卷考试:进行全卷评分,而不只针对单一题型,且包括带图的高考题考前开源:评测覆盖的开源模型均为今年高考前开源的模型,排除泄题的可能性老师打分:邀请有高考阅卷经验的老师打分,确保评分和高考尽量一致完全公开:生成答案的代码、模型答卷、评分结果完全开源在增加综合科目的基础上,阿里Qwen2-72B、GPT-4o、浦语文曲星包揽文科、理科前三甲。
其中,阿里Qwen2-72B 546分的成绩成为了「AI高考」的“文科状元”,浦语文曲星则以468.5分成为理科第一名,超越GPT-4o成为“理科状元”。
参与本次「AI高考」的阅卷老师一致认为:
大模型与人类考生之间仍然存在明显的差距,虽然AI对于基础知识的掌握表现出色,但在逻辑推理和知识灵活应用方面,大模型仍然差强人意。
具体而言,在作答主观题时,大模型往往无法完整理解题干,不明白代词指向,结果导致答非所问;解答数学题时,解题过程机械且逻辑性差,对于几何题,常出现与空间逻辑相违背的推断;对物理、化学实验理解肤浅,无法准确识别并运用实验器材。
此外,大模型也会经常出现伪造虚构内容的“AI幻觉”情况,编造看似合理但实际不存在的诗句,或在存在明显计算错误的情况下之后不反思,“硬着头皮蒙”一个答案,均给阅卷老师批阅试卷带来了困扰。
测评完整报告地址:https://github.com/open-compass/GAOKAO-Eval

 喜欢
喜欢
 顶
顶
 无聊
无聊
 围观
围观
 囧
囧
 难过
难过 SDXL跟LCM怎么在comfyUI中搭建工作流,_
SDXL跟LCM怎么在comfyUI中搭建工作流,_
 ChatGPTs保姆教程_ChatGPT使用教程_怎么自己生成GPT
ChatGPTs保姆教程_ChatGPT使用教程_怎么自己生成GPT
 小白必备lora炼丹技巧_lora模型怎么训练
小白必备lora炼丹技巧_lora模型怎么训练
 万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
 EbSynth插件怎么安装_stable diffusion视频转AI动画
EbSynth插件怎么安装_stable diffusion视频转AI动画
 美图AI鞋服设计怎么样_美图AI鞋服设计教程
美图AI鞋服设计怎么样_美图AI鞋服设计教程
 Kimi连夜上线PPT生成功能丨测评18款AIPPT产品
Kimi连夜上线PPT生成功能丨测评18款AIPPT产品