华为、腾讯的研究人员联合开源了创新视频模型——AniPortrait。
用户通过AniPortrait用音频和人物图片就能自动生成音频同步的视频,例如,让李云龙、新恒结衣、蔡徐坤的图片轻松唱歌、说话。
这与今年2月阿里集团发布的EMO模型,以及谷歌发布的VLOGGER在功能方面几乎一样,但那两个是闭源的。
开源地址:https://github.com/Zejun-Yang/AniPortrait
论文地址:https://arxiv.org/abs/2403.17694
AniPortrait生成的视频
AniPortrait的核心框架主要分为两大块,首先通过AI从语音中提取3D面部网格和头部姿态,然后将这些中间表示作为生成条件,用于生成逼真的人像视频序列。
Audio2Lmk音频提取模块
Audio2Lmk借助了语音识别模型wav2vec 2.0.从原始语音波形中提取丰富的语义表示,精准捕捉发音、语调等细微特征,为后续的面部动作捕捉奠定了基础。
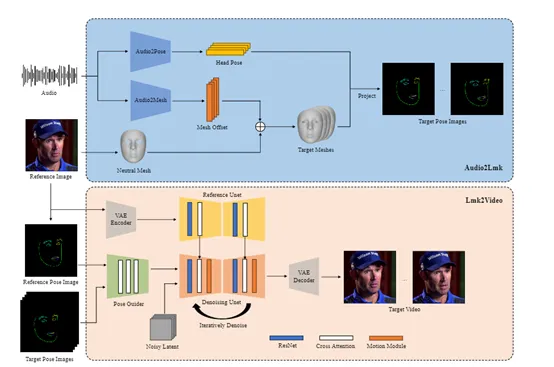
然后,研究人员设计了两个并行的小型网络,分别从wav2vec提取的特征中学习3D面部网格序列和头部姿态序列。
负责3D面部网格预测的是一个仅由两层全连接层组成的极简网络。虽然结构十分简单,但这种设计保证了高效运算,并极大提升了准确性。
为了增强头部姿态与语音的节奏、音调等因素关系更贴切一些,研究人员使用了Transformer解码器来捕捉这种细微的时序关联性。
该解码器的输入是wav2vec2.0提取的语音特征,在解码过程中,Transformer会通过自注意力和交叉注意力机制,自动学习语音与头部姿态之间的内在联系,最终解码出与音频节奏高度一致的头部姿态序列。
在训练阶段,研究人员使用了内部采集的近一小时高质量演员语音作为数据源,加上公开的人脸数据集HDTF。再通过监督学习的方式,提升了从语音到3D面部表情和头部姿态的高精度映射。
Lmk2Video视频生成模块
Lmk2Video的作用主要是将Audio2Lmk捕捉到的3D人脸数据和姿态数据渲染成高分辨率的视频。
Lmk2Video使用了目前在人物生成视频领域比较好的模型AnimateAnyone,能够通过给定的人体姿态序列作为条件,生成高质量、连贯自然的视频。

但是人的面部区域的细节远比身体更复杂,动作幅度也更小,需要极高的精度才能捕捉到微小的嘴型变化和面部肌肉运动。
原版AnimateAnyone的姿态引导模块仅由几层卷积层构成,将人体姿态数据编码后直接融合到主干网络的初级阶段。
这种设计在较大尺度的人体动作上还勉强可行,却难以准确捕捉面部细节。所以,研究人员对AnimateAnyone进行了改良。
他们将图片的人物面部关键点也作为输入,并通过注意力模块与目标关键点序列交互,使网络能更好地理解面部特征与整体外观之间的内在联系,进一步提升动画的精细度和一致性。
此外,为了增强网络对嘴型变化的敏感度,研究人员还将2D关键点渲染成姿态图像时,特意用不同颜**分上下嘴唇,这样网络就能更清晰地感知到微小的嘴型细节和变化趋势。

 喜欢
喜欢
 顶
顶
 无聊
无聊
 围观
围观
 囧
囧
 难过
难过 SDXL跟LCM怎么在comfyUI中搭建工作流,_
SDXL跟LCM怎么在comfyUI中搭建工作流,_
 ChatGPTs保姆教程_ChatGPT使用教程_怎么自己生成GPT
ChatGPTs保姆教程_ChatGPT使用教程_怎么自己生成GPT
 小白必备lora炼丹技巧_lora模型怎么训练
小白必备lora炼丹技巧_lora模型怎么训练
 二次元界欢呼,动漫风格神级工具更新丨AI绘图Niji V6全面上手评测
二次元界欢呼,动漫风格神级工具更新丨AI绘图Niji V6全面上手评测
 万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞